To understand the problems of dynamic type negotiation, the fundamental concept of Argot data encoding must be understood. Argot meta data definitions are a reflection of how the data is encoded in communications. This is the opposite of Abstract Syntax Notation(ASN1) which defines the abstract meta data of a structure and then applies one of various encodings when the data is being written.
For instance, I'll use the Address data type as an example:
(library.entryIn the above data definition, the address structure has three fields; street, suburb and state which are all defined as ASCII strings with a maximum length of 256 characters (u8ascii). Defining an instance of this in Argot would be:
(library.definition u8ascii:”address” u8ascii:”1.0”)
(sequence [
(tag u8ascii:”street” (reference #u8ascii))
(tag u8ascii:”suburb” (reference #u8ascii))
(tag u8ascii:”state” (reference #u8ascii))
]))
If this instance was to be serialised for communications it would look as follows:
(address street:”PO Box 4591” suburb:”Melbourne” state:”Victoria”)
0x0B “PO Box 4591” 0x09 “Melbourne” 0x08 “Victoria”Referring back to the address meta data you can see that this encoding shows a sequence of three strings. The u8ascii type uses a unsigned 8-bit byte to specify the length of each string before the data. Other than the length of each string before the string data there is no other meta data embedded into to encoding. This format has a number of consequences for how Argot must read data from the stream. The most important requirement is that Argot must know exactly how many fields each structure contains and what data is coming next. The advantage is that Argot is able to use a very compact data format with little to no meta data being utilised in the data stream. The disadvantage is that the exact structure of the data must be known before it can be read. This requires a client/server to both agree on the data types being used for communication.
(note strings have not been changed to hex to ease readability)
Remote Dynamic Data Type Agreement
When communicating between client and server using Argot, information such as the Address instance above are identified using a 16bit identifier. This identifier is assigned dynamically to allow the communication channel to dynamically discover the data types it can communicate between client and server (as was discussed in the Versioning Part 1). In Argot's current form this negotiation is quite simple. It involves the following transactions.
- Meta dictionary check – There is an initial call to the server which checks if the core meta dictionary data types are the same. These data types are assigned a common set of identifiers that both client and server must adhere. This operates as a bootstrap mechanism for other types to be defined. This boot strap mechanism allows the meta data to be expanded and include new concepts for how to describe the data being transferred that were not previously developed in the core of Argot's meta data.
- Resolve Identifier – When a client needs to send a data type for the first time (that is not in the meta dictionary list of types) it sends a “resolve” message to the server. This message has the type's name and structure. The server receives the message, finds the data type and decides if the data structures match. If they match, an identifier is assigned for the channel for that type; if they don't match, an error is returned to the client. If an agreement can not be found, then the client will receive an error and the message being sent must be aborted.
- Reserve – In some circumstances a data type will have a cyclic reference to itself. Before the data type structure can be resolved using the above call the client must assign an identifier so that its data structure meta data can be written. The reserve call sends a message with a type name to the server. If the server has a data type with the same name it assigns an identifier to the client. If the server does not have the specific data type name then an error is returned to the client.
- Resolve Reverse – When a server is responding to a request it may wish to send a client a data structure that has not been resolved by the client. Argot uses asynchronous request/response semantics for all calls. This means that the server is unable to initiate a request to the client to resolve the data structure. In this situation the server assigns an identifier and sends the data to the client. When the client reads an identifier it doesn't recognise, it makes a “resolve reverse” call to the server with the identifier. The server responds with the name and the data type meta data assigned to the identifier. If the client finds it has the same data structure it is able to continue reading the data. If the client does not find a match it must abort reading the data as it does not understand the data received.
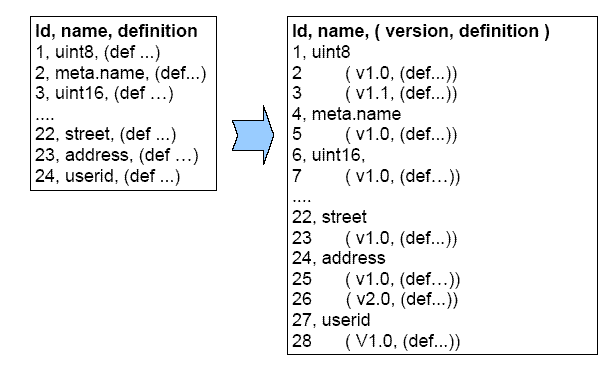
Adding versioning into Argot requires a location to be used instead of a name for all of the above calls. To a large extent, this is all that is required. However, there is a problem at the protocol level centred around the concept of “resolve reverse”. As stated above, currently the server has one version of each data type. When responding with a previously unused data type it is able to respond with the single version of the data structure. The client either reads the data or doesn't. In a situation where the server has multiple versions of the data structure it needs to know which version to send to the client. In a protocol that uses asynchronous request/reply semantics, the server is unable to initiate request to the client to ask which version to use.
Here's some ideas that were explored to solve this issue:
- Place holder – The server could return a place holder for the data instead of the actual data. This would require that the client must find this place holder in the data stream and send a message to the server.
This is not suitable as it puts a burden on the application to keep the instance data around to be encoded as required by the client. It also makes the Argot streaming interfaces very complex. - Second Channel – Require that the client hold open a second channel to the server. This allows the server to initiate requests such as this to the client. The client could close both channels when communications has completed.
This is not suitable as TCP sessions are a scarce resource. Keeping open a communications channel for the chance of communications is not appropriate. - Pause Stream – Stop the current response and return a message in the stream asking the client to resolve the version required. The client would resolve the version and then return a message to the server asking it to continue with the selected version.
This is not suitable as the client may be in the middle of reading any other data type. It may not be in a position to find the message in the stream.
- Chunked Stream – Require that a response stream is broken up into chunks. The server fills up a chunk before sending the response to the client. If the server finds a data type that needs a version selected, the server can initiate a request to the client asking which version to use. As the stream is chunked the client is able to receive requests from the server interleaved with the response stream.
The interesting part of this solution is it changes the underlying request/response semantics and opens up the stream to be a bidirectional group of channels. This aligns well with the asynchronous request/reply concept already stated in BORED (Binary Object REst Distributed system). Using a chunked stream is bringing the concepts of TCP up a layer to allow multiple communications to occur on the same channel. Allowing the server to initiate requests also creates a new set of opportunities and challenges. The chunked stream also has some similarities to SCTP, the protocol used in VOIP systems. - Pre-fetch – Require that the client know the type of data structures that will be returned by a request. The client must send a request to the server with all the data types that it could receive in the response.
Ideally the client would send a group of data types to the server for data type and version negotiation. An issue with this is that some data types may need to be resolved before the group can be sent. To resolve this, the client can use a set group of reserved identifiers for the purpose of performing type resolution.
- Negotiated Versioning – The discussion above revolves around the concept that the client and server require to negotiate the version of data they should use. This scenario would be most effective where a client and server have a communication which persists over a series of calls. This is especially true in environments that have multiple servers and clients with data that is evolving over time.
In negotiated versioning the server has a set of versions for each data type. The client is able to select which version it would like to communicate with for each type. - Shared Versioning – Another possible scenario is that both the client and server agree to adhere to a version dictated by separate server. In this scenario the server is able to send any data to the client as long as it adheres to the shared version. This may be appropriate for organisations wishing to centralise the data dictionary for better management purposes. It is also likely that the server will contain multiple versions of data types. The client would select a version of the dictionary which would select the correct version of each data type; much like a version in traditional version control systems. This is required as clients and servers programmed for a particular version of a data type can not have the structure of that type changed unexpectedly.
This scenario requires that the client or server select the server that will be used to select the data type version. - Server Dictated – In some cases the server may only have a single version of each data type. In this scenario there is no point attempting to negotiate the data types. The client must have the specific versions of data required by the client. This is scenario that Argot currently uses for communications. In scenarios where deploying new servers are more expensive and clients talk to many servers this is most appropriate. The client must contain all data type versions required to communicate with each server.
This case is also true for any form of message queueing or file base messages. The server will have no idea which version the client requires. If the server has multiple versions available then it will need to select the most appropriate version of each type for a given file. It is also true for embedded systems where the server will not have the resources or processing power to perform full negotiation of data types. - Client Pre-Selected – In some cases its most appropriate for the client to pre-select the data type versions it expects to receive from the server. In this scenario the client sends a group of data types and versions that the server should use for communications. In this scenario the client is more expensive to deploy or a server needs to communicate with multiple versions of a client.
This method fits into the pre-fetch method above. - Version Controlled – In this scenario the stream includes a version selector for a group of data types. This is more in-line with how many systems currently operate. The disadvantage of this mechanism is that every data type must be pre-selected to be part of the group of a selected version.
If you can think of other methods of performing version agreement between servers please let me know so that I can add it to the list.
Catering for the various types of version management in a single protocol is not a simple task. The protocol redesign should also align with the BORED protocol discussed in previous posts. In addition to these requirements the final requirement is to build security into the protocol. These issues will be explored in a later post.
Argot Programming Model
Another piece in the versioning puzzle is how the programmer's API has changed for the most common functions of Argot. In the current system, Argot uses the concept of a TypeMap for mapping specific data types to a stream. Currently this does not include any type of version information. Some example code looks like:
TypeMap map = new TypeMap( typeLibrary );In this scenario, the user is mapping a local identifiers to data types in the type library. To support versioning, the developer would need to specify which version of u8 and u8ascii they wanted from the TypeLibrary.
map.map( 1, typeLibrary.getId(“u8”));
map.map( 2, typeLibrary.getId(“u8ascii”));
TypeMap map = new TypeMap( typeLibrary );The problem with this is it re-introduces a specific version too early in the communications. The solution is the introduction of a TypeMapper interface which is passed into the TypeMap. The TypeMapper has the task of selecting which version of a data type is required at the time it is being used. The user simply creates the TypeMap with the required TypeMapper. The TypeMap initialises the TypeMapper which gives it a chance to map any required types. When a developer writes a data type that is not in the map, the TypeMapper is called which resolves which version of a type to use. Creating a type map now looks like:
map.map( 1, typeLibrary.getId(“u8”, “1.0.0”));
map.map( 2, typeLibrary.getId(“u8ascii”, “1.0.0”));
TypeMap map = new TypeMap( typeLibrary, new TypeMapperDynamic());In this case a dynamic type map is being used to resolve the data types. It dynamically assigns any types required by the type map. A stream is created and written using:
typeStream = new TypeOutputStream( stream, map );If we were to write a specific version, the API would change to:
typeStream.writeObject( “address”, addressObject );
typeStream.writeObject( “address”, “1.2”, addressObject );Once again this re-introduces a specific version too early. If the line above was on a server, any client or receiver of the data would be locked in to version 1.2 of the address. For this reason the first example is how objects should be written to the stream. This requires that the TypeMapper select the correct version of the address type.
Different type mappers can be created to deal with the various styles of type negotiation listed above. After an id has been mapped, any use of that name will tie directly to the specified version.
Meta Dictionary Update
Near the end of the last post I suggested a change to the meta dictionary which had the effect of only allowing a single version of any data type to be used on a stream. The requirement at the API to only use the name and not the version validates that this change would match the API. The meta dictionary has been updated to reflect this change. This changes very little in actual meta dictionary.
A consequence of this change is that an additional request/response pair is required for the traditional method of performing type agreement. The first time a client wishes to use a type it must send to the server the name of the type without specifying the version. The server maps a specific version to the type and returns the mapped identifier, the location of the definition and the definition structure. The client is able to check this against its local version. This method continues to use server dictated versioning and is a temporary solution until a more advanced protocol can be devised.
Another small update to the meta dictionary is naming. Currently types in Argot are defined using a short ascii string (e.g. “meta.abstract.map” ). In the meta dictionary this is defined as:
(library.entryWhile the string implies that the name has groupings, each name is simply a unique string. As the number of objects in the TypeLibrary increases it will become more difficult to find specific groups of types. The string also goes against a central concept of Argot; there's no need to define string based expressions for encodings. The solution is to change the meta.name to:
(library.definition u8ascii:"meta.name" meta.version:"1.3")
(meta.reference #u8ascii))
(library.entryThis creates an array of name parts which is a more true representation of the name. This allows the TypeLibrary to build a hierarchy in the type library. For programmer simplicity a parser is still used for the text representation. However it would still be possible to write one of the entries above as:
(library.definition
meta.name:"meta.name_part" meta.version:"1.3")
(meta.reference #u8utf8))
(library.entry
(library.definition
meta.name:"meta.name" meta.version:"1.3")
(meta.array
(meta.reference #uint8)
(meta.reference #meta.name_part”)))
(library.entryAnother small change is from u8ascii to u8utf8. This allows a wider variety of languages to be used for names. In the future I'll introduce a meta.alias type as an extension to the meta dictionary. This will allow different languages (I.e. Spanish, Japanese, etc.) to define their own names for data types while still keeping compatibility.
(library.definition
(meta.name [ u8utf8:“meta” u8utf8:”name_part ] )
(meta.version major:1 minor:3))
(meta.reference #u8utf8))
Object Relationships
Another issue to add to the list. How to you deal with the relationship between data types and data objects across multiple versions. The whole point of Argot is to create a simple API for making it easy to read/write data to/from data streams. In essence to communicate knowledge between systems.
When binding a Java class to the TypeLibrary, is the Name or the data type definition version used? If the same class can be used for all Definitions then binding to the name is appropriate. If different classes are required between versions then binding to the definition is required. All definitions should define a common interface or super class. If this is not the case then the developer must be very careful not to create data streams that intermix objects as class cast exceptions will be likely. This is another area which is not fully developed and will need to be explored. However, relative to the versioning base meta data changes, this is a small task.
Conclusion
The Argot library now supports versioning, however, there's still some loose ends to tidy up. Future posts will explore the some of these loose ends. Version 1.3.0 which includes versioning is currently being cleaned up and will be released in the next week or two.